

.jpeg)
Building the Coordination Layer Your AI Agents Don't Know They Need
Your agents have memory. They have tools and structured reasoning. They can select the right API, format the right output, and recover from a surprising number of individual failures. What they cannot do, and what no amount of framework improvement will teach them to do, is see each other.
This is not a metaphor. An individual agent operating inside a multi-agent system has no awareness of what the other agents are doing. It does not know that three other workflows are hammering the same dependency. It cannot detect that its retry pattern is correlated with the retries of every other agent in the swarm. It has no concept of drift, the slow degradation of an upstream service that has not yet failed but is about to take everything downstream with it when it does.
Agent frameworks have made a reasonable design decision here. They are opinionated about local logic, about tool selection, structured outputs, and workflow composition, and they are intentionally unopinionated about coordination across the system. This is great for developer experience. It is also, in production, where things start to go seriously wrong.
The problem with emergent coordination
When coordination is not explicitly owned by something in the architecture, it does not disappear. It becomes emergent. And emergent coordination is a polite name for a system that is coordinating by accident.
The consequences are predictable and well-documented by anyone who has run distributed systems at scale. Retries correlate. Fanout amplifies. A single degraded dependency produces not one failure but a cascade of expensive, redundant attempts to reach it. The system becomes its own adversary, each agent rationally pursuing its local objective while collectively producing an outcome that is irrational, wasteful, and increasingly difficult to debug after the fact.
The standard response to this is observability. Add more logging. Build better dashboards. Instrument every call. This is necessary work, and it is also entirely retrospective. Observability tells you what went wrong. It does not prevent the next cascade. It gives you a clearer postmortem, which is valuable, but it does nothing about the fundamental structural problem: nothing in the system is watching the coordination itself as it happens.
What a coordination layer actually does
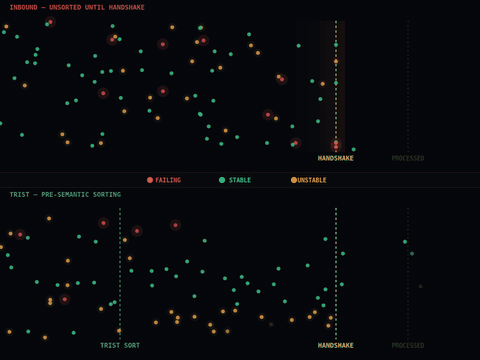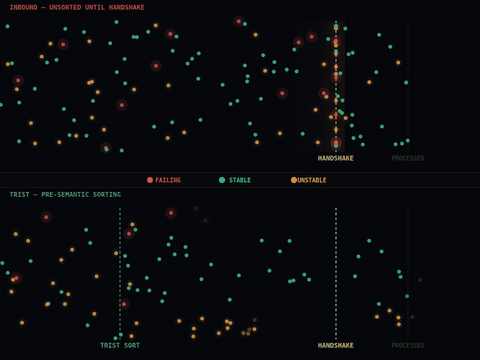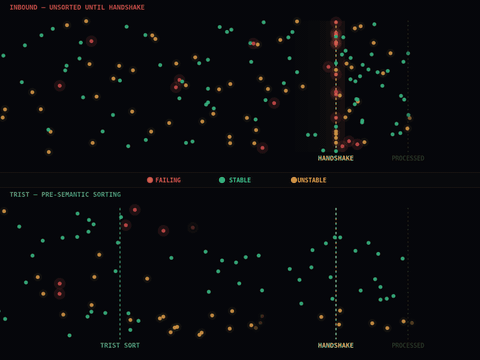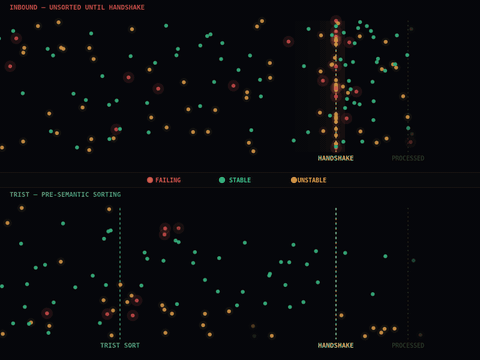
The layer that is missing is not a smarter agent. It is infrastructure that sits between agents and the resources they consume, shaping what arrives at them and what leaves them based on behavioral signals rather than content.
This distinction matters. A coordination layer that reads prompts and responses to make decisions is a semantic system, with all the compliance burden, latency cost, and privacy exposure that comes with inspecting content. A coordination layer that operates on timing, frequency, sequence, and fanout patterns is something fundamentally different. It can see the structural signature of a cascade forming before any individual agent has encountered an error. It can detect drift, the slow compression of response times or the subtle shift in retry patterns that indicates a system moving toward failure, and act on that signal before the failure materializes.
The practical effect is that you can adopt this kind of layer without rewriting your agent logic. Your agents continue doing exactly what they do. The coordination environment around them changes.
What this looks like in production
The clearest way to understand the value is through the scenarios where coordination failures are already costing real money.
Consider a multi-agent KYC workflow during an identity provider degradation. Without coordination awareness, every agent in the system independently retries the degraded provider, producing correlated retry storms that can trigger rate limits and lockouts. The degradation becomes an outage, manufactured by the system's own behavior. With coordination, the system detects the drift, holds or defers affected workflows, and resumes cleanly when the provider stabilizes. The difference between these two outcomes is often the difference between a minor latency increase and an operational incident.
Or consider a voice AI system during a traffic spike. Without coordination, fanout grows linearly with traffic while the system's ability to absorb that fanout does not. Non-critical work competes with latency-sensitive work for the same resources. With coordination, you can shape the fanout, defer non-critical processing, and protect the core experience without dropping calls or degrading quality for the user who is actually on the line.
The pattern repeats across multi-model inference when a provider wobbles, across RAG pipelines when vector database latency creeps upward, and across agent swarms where a single tool failure propagates through cascading dependencies. In each case, the issue is not the intelligence of any individual component. The issue is that nobody is watching the interaction patterns, and by the time observability surfaces the problem, the damage is already on the invoice.
Where this layer lives
There is no single correct integration point. The right placement depends on where in your architecture interaction flows are visible and controllable.
For teams building directly on agent frameworks, wrapping tool and model calls with behavior capture at the middleware level is the lightest touch. For multi-tenant platforms, enforcement at the gateway provides policy-level coordination across workloads that share infrastructure. For teams using orchestrators with durable execution, hooks at the orchestration layer give you visibility into sequences and the ability to hold, defer, and reshape workflows in progress. For teams that want coordination adjacent to runtime without deep integration, a sidecar pattern keeps the control plane close while minimizing the surface area of changes to existing code.
The point is not that one of these is correct and the others are wrong. The point is that coordination control can be adopted incrementally, at the boundary that makes sense for your architecture, without requiring you to rebuild what already works.
Coordination value is not linear
There is a mathematical reality to multi-agent systems that is worth stating plainly: coordination value grows faster than agent count.
In a system with two agents, the interaction surface is small. In a system with ten, interactions multiply combinatorially. One agent's retry becomes another agent's congestion. One agent's fanout becomes the system's resource ceiling. The costs that were manageable at small scale become the dominant line item at production scale, and they become so not gradually but suddenly, in the way that distributed systems tend to surprise the people who build them.
This is the reason that coordination cannot be deferred indefinitely. The problem does not stay the same size while you wait. It grows with every agent you add, every workflow you compose, and every dependency you integrate. Teams that address it early build on a foundation that scales with them. Teams that defer it discover, eventually, that retrofitting coordination into a system designed without it is significantly more expensive than building on it from the start.
Starting the measurement
The most useful thing a team can do right now is capture behavioral signals at tool and model boundaries for one expensive workflow. Not to build a coordination system from scratch, but to see the data. Count the correlated retries. Map the fanout amplification. Look at how tail latency distributes across the workflow when an upstream dependency drifts.
The numbers tend to settle the question of whether this layer matters. What follows is a conversation about architecture, not about whether the problem exists.
Tethral builds pre-semantic coordination infrastructure for agentic AI systems, reducing wasted inference spend, cascading retries, fanout amplification, and tail latency without inspecting content. Design partner inquiries: info@tethral.ai
RELATED POSTS











.jpg)





